
Opinion
Going Deep on Privacy: MimbleWimble (Part 3)
This is Part 3 of this series. Click here for Part 1 and Part 2.
New Coins on the Block
Grin and Beam are two of the newest privacy coins to come to market. They are both implementations of a proposed design for a new blockchain called MimbleWimble, which has generated significant buzz in the blockchain community due to a) its elegant proposal for a privacy blockchain and b) its bitcoin-esque origin.
Block Pruning
The second unique feature inherent to MimbleWimble, because of its scriptless design, is its ability to effectively “block prune”. To understand how to prune a blockchain, we need to explain how blockchains and the blocks themselves are structured/formatted in the first place. If you’re not familiar with merkle trees, this will involve a mind shift as to how you think about and visualize blockchains, so buckle in.
At a high level, we visualize blockchains as blocks of data connected by links, where the links cannot be broken and the next block depends on its predecessor. But under the hood, each of these blocks is organized using a merkle tree data format. Blocks are not linked in a series format (1 →2 →3) but rather in an optimized, hierarchical structure.
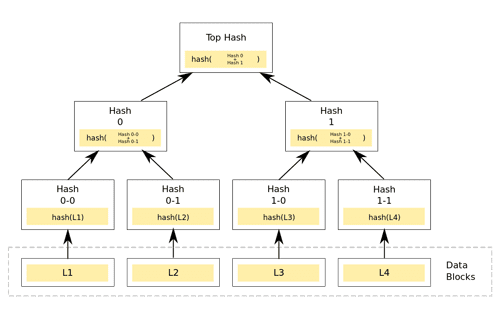
Visual representation of a merkle tree in a block. Source: Wikipedia Commons.
Think of merkle trees as inverted versions of our trees in nature. The “leaves” are the transactions between senders and receivers — L1, L2, L3 and L4. The “branches” are the hashes, re-hashes, and combinations of those transactions until you end with the “root”. The “merkle tree root,” which is the top box, is the final hash of the transaction data. So in the previous section above, when I list all the transaction inputs and outputs included in a MimbleWimble block, that data is organized in a merkle tree-like format (Grin actually uses a Merkle Mountain Range (MMR) structure for its data organization, which is a merkle tree variant).
The merkle tree root is then included in the current block’s header (see below), along with another hash — the hash of the previous block header, which allows us to link the current block to the previous block, thereby creating the dependability/linkage in blockchains. If some malicious node were to try to change a historical transaction, the change would carry up the merkle tree and connect to all the following blocks via the block headers.
Below, the figure on the left (from Satoshi’s Original Bitcoin Whitepaper) illustrates one block in the blockchain nicely, with the merkle tree sitting below the block header and supplying the block header with the merkle tree root.
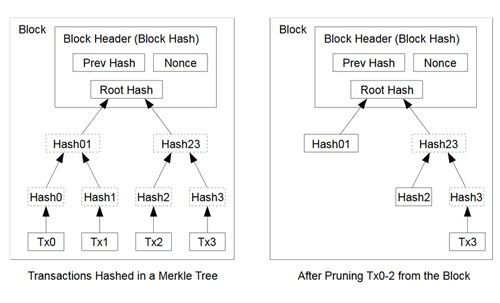
Visual representation of simplified Bitcoin blocks. Source: Original Bitcoin Whitepaper.
The figure on the right, also taken from Satoshi’s white paper, represents the block pruning. Why the name block pruning, you may ask? Because in english, the verb “to prune” means to trim a tree, shrub, or bush by cutting away dead or overgrown branches or stems. Satoshi originally proposed that in Bitcoin, you can prune away unnecessary, historical merkle tree leaves and branches without compromising validation for current transactions.
What transactions was Satoshi referring to as unnecessary — don’t all transactions matter in the blockchain? The most obvious answer, and the biggest problem for the size of blockchains, are duplicate transactions. If you’ve ever sent 10 Bitcoin (BTC) to another party and watched the block explorer, it is highly likely you would see your 10 BTC move to an intermediary public key (also owned by you) before it reaches the address of the recipient. A lot of times this is done to properly balance inputs and outputs. However, in our example 10 BTC was a duplicate transaction to two addresses, when it really only needed to be sent to one. Frequently in Bitcoin, when a block is filled with transactions, those transactions contain these intermediary sends. Duplicate transactions contribute to alarming amount of data found in unpruned, scripted blockchains today.
In scripted blockchains, it is difficult to prune these duplicate transactions from a block because of the scripted public keys involved in the transaction hashes. If Bob sends Alice 2 BTC and Alice sends Caroline 2 BTC, because their public keys are included in the transaction hash, its probabilistically impossible and would be computationally exhausting to unwind the public keys of an intermediary every time a duplicate is identified. However, in scriptless MimbleWimble it’s a different ball game, which has opened the door for effective blockchain pruning.
MimbleWimble can blockchain prune both in the same block and across blocks. By reviewing the transactions in conjunction with their transaction kernels, the MimbleWimble protocol can figure out if duplicate UTXO’s are apart of the same block and prune them away. The logic holds when applying this same concept to pruning the entire blockchain. Let’s say Bob sends Alice 10 BTC on day 1. A few days and blocks later, Alice sends Caroline 20 BTC, 10 of which came from Bob. That UTXO of 10 BTC has now been spent; hence, that UTXO of 10 BTC from Bob to Alice can now be removed from the merkle tree on day 1. The MimbleWimble blockchain retroactively prunes blocks to ensure that there are now unnecessary duplicates of UXTOs, but retains the transactions kernels of those duplicates to mathematically prove the existence of those duplicate transactions.
The ability to prune duplicates across the MimbleWimble blockchain yields substantial space savings and therefore cost savings for validating nodes. According to the Grin team, assuming 10 million transactions with 100,000 unspent outputs, the ledger will be roughly 130GB (128GB of transaction data (inputs and outputs), 1 GB of transaction proof data, and 250MB of block headers). The total storage requirements can be reduced if cut-through and pruning is applied, the ledger will shrink to approximately 1.8GB (UTXO size of 520MB, 1 GB of transaction proof data, 250MB of block headers). That’s a ~98% reduction in size! As we mentioned in our previous privacy report — when you don’t tell everyone, everything, you theoretically can save time and space.
One of the important trade-offs to address with MimbleWimble’s blockchain design is that its scriptless design limits its interoperability. Because most of the other protocols use scripted code, MimbleWimble cannot support smart-contract functionality and all that’s included such as state channels, cross-chain atomic swaps, etc. In addition to the script incompatibility, blockchain pruning causes significant challenges for smart contracts compatibility because relevant UTXO’s involved in a smart contract might be deleted. Because this incompatibility hinders MimbleWimble’s ability to scale beyond functioning as a medium of exchange, Andrew Polestra, in March 2017 developed a language within MimbleWimble called “scriptless scripts,” which allows for smart contract integration in MimbleWimble. That said, scriptless scripts are limited in scope and ability compared to the scripted languages used in other blockchain protocols.
Scriptless scripts are not designed exclusively for MimbleWimble; any scriptless platforms can implement them for smart contract integration. However for current scriptless scripts, blockchain validators only require and confirm that signatures are present and correct. According to Adam Gibson, a Bitcoin privacy cryptographer, scriptless scripts can enable functionality like Atomic swaps and Lightning network like payment channels. Beam is currently building a compatible lightning network using scriptless scripts.
Dandelion
Dandelion is an alternative proposal to Kovri, I2P and Tor for securing transmission privacy that has been implemented by Grin and Beam. It was originally proposed as a solution for Bitcoin in June 2017, which was followed up by Dandelion++ in May 2018 (Dandelion++ is an improved version of Dandelion that defends against stronger adversaries that could thwart the protocol of the original).
Dandelion was developed by Guilia Fanti, an assistant professor of Electrical and Computer Engineering at Carnegie Mellon University, and a team of professors from the University of Illinois including assistant professor of Electrical and Computer Engineering Andrew Miller, who funny enough is an advisor to ZCash. ZCash has not implemented Dandelion to date. Rather than creating an alternative transmission layer, Dandelion is a transaction routing mechanism that essentially challenges the way nodes transmit packets after Dijkstra’s algorithm determines the shortest path, which is known as “diffusion”. The predictability of movements from a sender using diffusion allows for network adversaries to more easily spy on active nodes and link transactions to IP addresses. Rather than using diffusion, Dandelion sends transactions over a randomly selected path before diffusion kicks in. The random path is known as the “stem phase,” and the subsequent diffusion, commencing at a random node, is known as the “fluff phase” — hence the name of the routing mechanism “Dandelion.”
This is Part 3 of this series. Click here for Part 1 and Part 2.



spravki-kupit.ru
June 26, 2023 at 6:16 PM
диплом о высшем образовании проверенный
June 27, 2023 at 1:17 PM
Hey There. I found your blog the use of msn. This is a very well written article. I will be sure to bookmark it and come back to read more of your useful information. Thank you for the post. I will definitely comeback.
гостиничные чеки купить спб
July 3, 2023 at 8:12 PM
Really no matter if someone doesn’t know after that its up to other viewers that they will help, so here it occurs.
bezogoroda.ru
July 4, 2023 at 1:50 PM
I like it when people come together and share thoughts. Great website, continue the good work!
гостиничные чеки купить спб
July 4, 2023 at 6:35 PM
Do you have a spam issue on this website; I also am a blogger, and I was curious about your situation; many of us have created some nice procedures and we are looking to swap solutions with other folks, be sure to shoot me an e-mail if interested.
online casino fake money
July 5, 2023 at 5:57 PM
Simply wish to say your article is as astonishing. The clearness in your post is simply cool and i can assume you are an expert on this subject. Well with your permission allow me to grab your RSS feed to keep up to date with forthcoming post. Thanks a million and please continue the gratifying work.
daachka.ru
July 6, 2023 at 1:52 PM
Every weekend i used to go to see this website, because i want enjoyment, since this this website conations in fact good funny data too.